通信协议
BitmapDrawable
微服务
费用流
人脸识别
jenkins
二维码
寒武纪面试
样本熵
消息传递
网络字节序
flutter
CLIP
makefile
图像像素点测量温度
esp8266wifi
线程同步
安卓
java-ee
mount
tf-idf
2024/4/12 2:31:31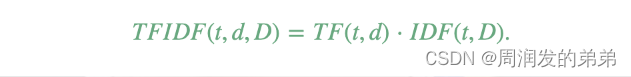
【SparkML系列3】特征提取器TF-IDF、Word2Vec和CountVectorizer
本节介绍了用于处理特征的算法,大致可以分为以下几组:
提取(Extraction):从“原始”数据中提取特征。转换(Transformation):缩放、转换或修改特征。选择(Selection&…

Python TF-IDF计算100份文档关键词权重
上一篇博文中,我们使用结巴分词对文档进行分词处理,但分词所得结果并不是每个词语都是有意义的(即该词对文档的内容贡献少),那么如何来判断词语对文档的重要度呢,这里介绍一种方法:TF-IDF。 一,TF-IDF介绍 TF-IDF(Term Frequency–Inverse Document Frequency)是一种…
tf-idf +逻辑回归来识别垃圾文本
引入相关包
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, auc, roc_auc_score
import joblib
import os
import pandas as pd
from sklearn.model_select…
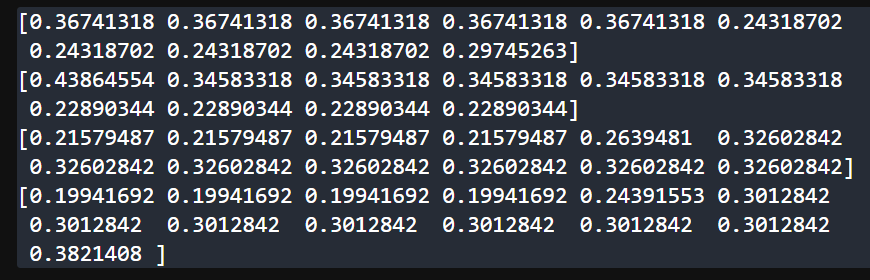
sklearn 计算 tfidf 得到每个词分数
from sklearn.feature_extraction.text import TfidfVectorizer# 语料库 可以换为其它同样形式的单词
corpus [list(range(-5, 5)),list(range(-6,4)),list(range(12)),list(range(13))]# corpus [
# [Two, wrongs, don\t, make, a, right, .],
# [The, pen, is, might…
如何搭建个人邮件服务hmailserver并实现远程发送邮件
文章目录 1. 安装hMailServer2. 设置hMailServer3. 客户端安装添加账号4. 测试发送邮件5. 安装cpolar6. 创建公网地址7. 测试远程发送邮件8. 固定连接公网地址9. 测试固定远程地址发送邮件 hMailServer 是一个邮件服务器,通过它我们可以搭建自己的邮件服务,通过cpolar内网映射工…
![[特征工程]Chap4. 特征缩放:TF-IDF](https://img-blog.csdn.net/20180504014354961?watermark/2/text/aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L25lbW95eQ==/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/70)
[特征工程]Chap4. 特征缩放:TF-IDF
本章通过BOW 到tf-idf的变化,讨论 feature scaling 的效果.
TF-IDF: BOW的变种
tf-idf可以说就是BOW基础上的变种, 全称: term frequency- inverse document frequency ,中文: 词频-逆文件频率.
BOW记录文件中的词频, 明显的问题就是会强调一些没意义的词, 如英文中的 the and …
![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)
集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]
搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术细节以及项目实战(含码源) 专栏详细介绍:搜索推荐系统专栏简介:搜索推荐全流程讲解(召回粗排精排重排混排)、系统架构、常见问题、算法项目实战总结、技术…

为什么嵌入通常优于TF-IDF:探索NLP的力量
塔曼纳 一、说明 自然语言处理(NLP)是计算机科学的一个领域,涉及人类语言的处理和分析。它用于各种应用程序,例如聊天机器人、情绪分析、语音识别等。NLP 中的重要任务之一是文本分类,我们根据文本的内容将文本分类为不…
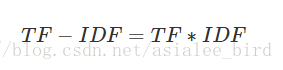
阅读——TF-IDF算法
博文TF-IDF算法介绍及实现主要介绍了TF-IDF,包括原理、不足、实战。阅读问题的提出中包含了对TF-IDF的拓展。 TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information …
传统词嵌入方法的千层套路
诸神缄默不语-个人CSDN博文目录
在自然语言处理(NLP)领域,词嵌入是一种将词语转换为数值形式的方法,使计算机能够理解和处理语言数据。 词嵌入word embedding也叫文本向量化/文本表征。 本文将介绍几种流行的传统词嵌入方法。 文…
在文本关键词提取中TF-IDF和TextRank算法结合使用的步骤
目录
一、实现步骤
二、怎样进行归一化处理
1. 对TF-IDF值进行归一化处理,
2. 对TextRank得分进行归一化处理,
3. 对TF-IDF值和TextRank得分进行加权和,
三、示例代码-使用python实现 TF-IDF和TextRank算法可以结合使用来提高关键词提取…

文本分析-使用jieba库实现TF-IDF算法提取关键词
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…

利用tf-idf对特征进行提取
TF-IDF是一种文本特征提取的方法,用于评估一个词在一组文档中的重要性。
一、代码
from sklearn.feature_extraction.text import TfidfVectorizer
import numpy as npdef print_tfidf_words(documents):"""打印TF-IDF矩阵中每个文档中非零值对应…
文本分类心得(Bert模型使用)
正式入职了一段时间,接手了NLP相关任务,作为一个初学者,分享一点最近的所学心得和体会。
稍后有时间更新,现在项目催的很紧,能力比较强的可以找我内推阿里秋招。可以私信我联系方法,个人会进行第一遍简历筛…

阿里云-零基础入门NLP【基于机器学习的文本分类】
文章目录 学习过程赛题理解学习目标赛题数据数据标签评测指标解题思路TF-IDF介绍TF-IDF 机器学习分类器TF-IDF LinearSVCTF-IDF LGBMClassifier 学习过程
20年当时自身功底是比较零基础(会写些基础的Python[三个科学计算包]数据分析),一开始看这块其实挺懵的&am…

自然语言处理NLP:tf-idf原理、参数及实战
大家好,tf-idf作为文体特征提取的常用统计方法之一,适合用于文本分类任务,本文将从原理、参数详解和实际处理方面介绍tf-idf,助力tf-idf用于文本数据分类。
1.tf-idf原理
tf 表示词频,即某单词在某文本中的出现次数与…
《机器学习系统设计》之应用scikit-learn做文本分类(上)
前言: 本系列是在作者学习《机器学习系统设计》([美] WilliRichert)过程中的思考与实践,全书通过Python从数据处理,到特征工程,再到模型选择,把机器学习解决问题的过程一一呈现。书中设计的源代…
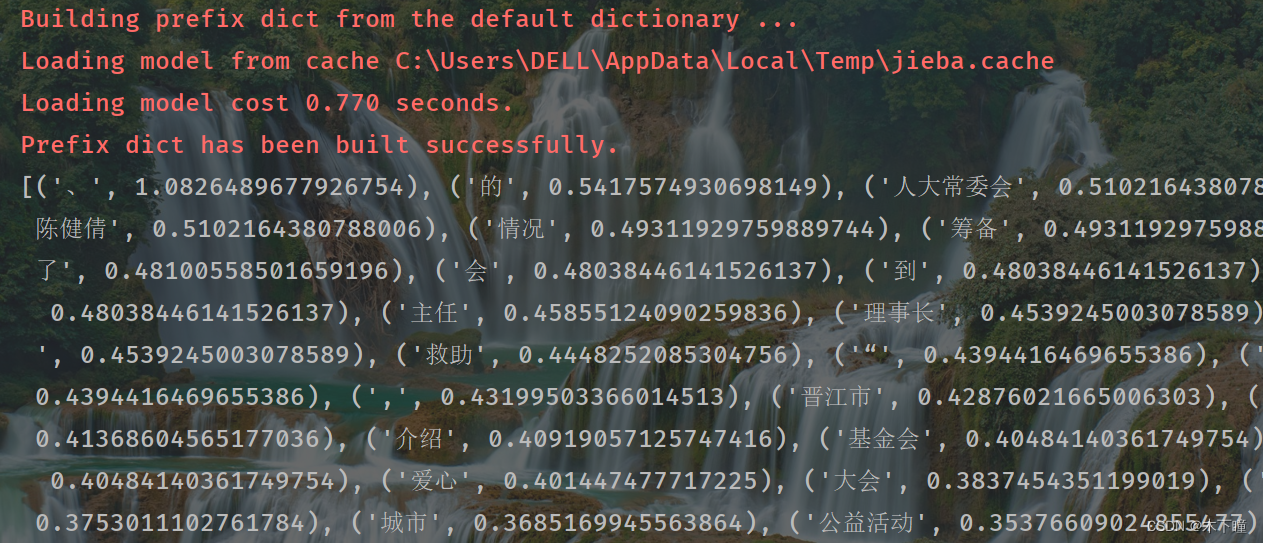
gensim 实现 TF-IDF
目录
介绍
代码 介绍
TF-IDF(Term Frequency-Inverse Document Frequency)
含义: TF (Term Frequency): 词频,是指一个词语在当前文档中出现的次数。它衡量的是词语在文档内部的重要性,直观上讲,一个词…

自然语言处理 TF-IDF
✅作者简介:人工智能专业本科在读,喜欢计算机与编程,写博客记录自己的学习历程。 🍎个人主页:小嗷犬的个人主页 🍊个人网站:小嗷犬的技术小站 🥭个人信条:为天地立心&…

TF-IDF,textRank,LSI_LDA 关键词提取
目录
任务
代码
keywordExtract.py
TF_IDF.py
LSI_LDA.py
结果 任务
用这三种方法提取关键词,代码目录如下,
keywordExtract.py 为运行主程序
corpus.txt 为现有数据文档
其他文件,停用词,方法文件 corpus.txt 可以自己…
sklearn中tfidf的计算与手工计算不同详解
sklearn中tfidf的计算与手工计算不同详解 引言:本周数据仓库与数据挖掘课程布置了word2vec的课程作业,要求是手动计算corpus中各个词的tfidf,并用sklearn验证自己计算的结果。但是博主手动计算的结果无论如何也与sklearn中的结果无法对应&…

无监督关键词提取算法:TF-IDF、TextRank、RAKE、YAKE、 keyBERT
TF-IDF
TF-IDF是一种经典的基于统计的方法,TF(Term frequency)是指一个单词在一个文档中出现的次数,通常一个单词在一个文档中出现的次数越多说明该词越重要。IDF(Inverse document frequency)是所有文档数比上出现某单词的个数,通常一个单词…
TF-IDF(词频-逆文档频率)
文章目录 高频词只能说明词汇在评论中出现的频率高,但并不能说明这个词汇的重要性。利用关键词提取可以弥补这一不足,关键词提取是一种自动化的文本处理技术,它可以从一篇文章中自动抽取出最能代表文章主题和内容的若干个词语或短语。通常情况…

中文分词和tfidf特征应用
文章目录 引言1. NLP 的基础任务 --分词2. 中文分词2.1 中文分词-难点2.2 中文分词-正向最大匹配2.2.1 实现方式一2.2.2 实现方式二 利用前缀字典 2.3 中文分词-反向最大匹配2.4 中文分词-双向最大匹配2.5 中文分词-jieba分词2.5.1 基本用法2.5.2 分词模式2.5.3 其他功能 2.6 三…
ElasticSearch 了解文本相似度 TF-IDF吗?
是的,ElasticSearch了解文本相似度中的TF-IDF(Term Frequency-Inverse Document Frequency)算法。TF-IDF是一种用于衡量文档中词语重要性的度量方法,常用于文本搜索和文本相似度比较。
在ElasticSearch中,TF-IDF可以通…

Lucene源码(二):文本相似度TF-IDF原理
Lucene中TF-IDF的计算公式与普通的TF-IDF不一样。学习之后,感觉Lucene的计算方法更加合理,考虑得更加周全。 q:query,即搜索内容,例如:github
d:document,即文档内容,例…
基于TF-IDF算法个人文件管理系统——机器学习+人工智能+神经网络(附Python工程全部源码)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 词频计算与数据处理3. 数据计算与对比验证 系统测试工程源代码下载其它资料下载 前言
本项目旨在通过应用TF-IDF算法,将新下载的课件进行自动分类整理。我们的方法是通过比较新文件中的…


【机器学习】TF-IDF以及TfidfVectorizer
TF-IDF定义
TF-IDF: 全称为"词频一逆文档频率"。 TF:某一给定词语在该文档中出现的频率。 T F w 词语 w 在该文档中个数 该文档内总词个数 TF_w \frac{词语w在该文档中个数}{该文档内总词个数} TFw该文档内总词个数词语w在该文档中个…
![[机器学习]TF-IDF算法](https://img-blog.csdnimg.cn/direct/87fcdb2e1e484015ac3e7e9f384d5845.png)
[机器学习]TF-IDF算法
一.TF-IDF算法概述 什么是TF-IDF? 词频-逆文档频率(Term Frequency-Inverse Document Frequency,TF-IDF)是一种常用于文本处理的统计方法,可以评估一个单词在一份文档中的重要程度。简单来说就是可以用于文档关键词的提…
建模杂谈系列240 增量TF-IDF2-实践
说明
梳理一下tf-idf的全过程,然后用于实际的需求中。
内容
1 概念
从数据的更新计算上,将TF-IDF分为两部分:一部分用于计算IDF的增量部分,属于全局的学习;另一部分则用于批量处理新的数据集,相当于是在…
基于TF-IDF的关键词提取的实现
一.TF-IDF的简单介绍
TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术,用于评估一个词在文档集合中的重要性。它结合了词频和逆文档频率的概念。
以下是TF-IDF的简单介绍:
词频…
《数学之美》第三版的读书笔记一、主要是马尔可夫假设、隐马尔可夫模型、图论深度/广度、PageRank相关算法、TF-IDF词频算法
1、马尔可夫假设 从19世纪到20世纪初,俄国有个数学家叫马尔可夫他提出了一种方法,假设任意一个词出现的概率只同它前面的词有关。这种假设在数学上称为马尔可夫假设。
2、二元组的相对频度 利用条件概率的公式,某个句子出现的概率等于每一个词出现的条件概率相乘,于是可展…

【NLP】TF-IDF算法原理及其实现
🌻个人主页:相洋同学
🥇学习在于行动、总结和坚持,共勉! #学习笔记#
目录
01 TF-IDF算法介绍
02 TF-IDF应用
03 Sklearn实现TF-IDF算法
04 使用TF-IDF算法提取关键词
05 TF-IDF算法的不足 TF-IDF算法非常容易理…
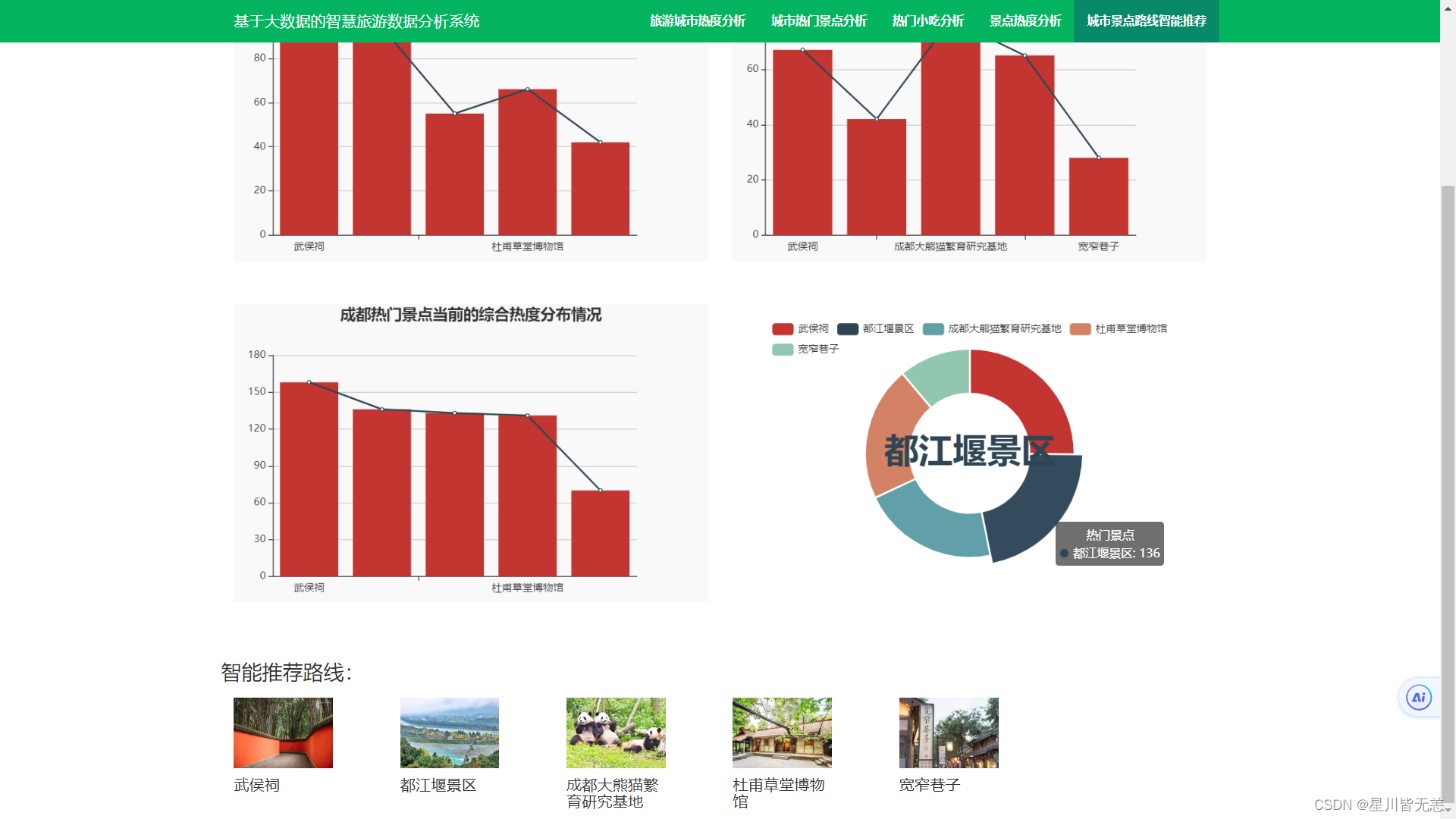
基于大数据机器学习TF-IDF 算法+SnowNLP的智慧旅游数据分析可视化推荐系统
文章目录 基于大数据机器学习TF-IDF 算法SnowNLP的智慧旅游数据分析可视化推荐系统一、项目概述二、机器学习TF-IDF 算法什么是TF-IDF?TF-IDF介绍名词解释和数学算法 三、SnowNLP四、数据爬虫分析五、项目架构思维导图六、项目UI系统注册登录界面各省份热门城市分析…
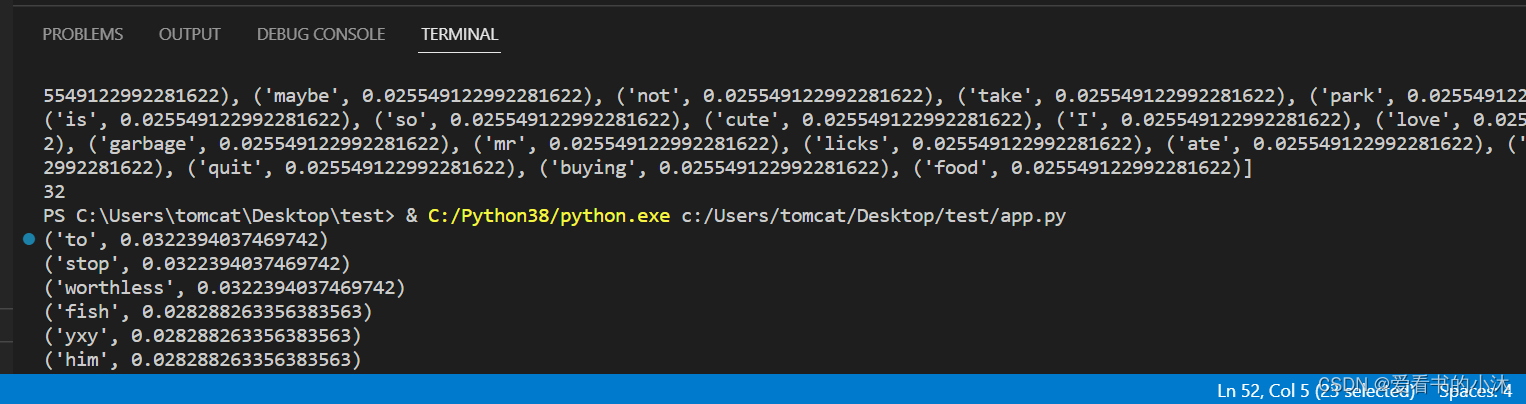
【小沐学NLP】Python实现TF-IDF算法(nltk、sklearn、jieba)
文章目录 1、简介1.1 TF1.2 IDF1.3 TF-IDF2.1 TF-IDF(sklearn)2.2 TF-IDF(nltk)2.3 TF-IDF(Jieba)2.4 TF-IDF(python) 结语 1、简介
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。TF是词频(Term Fr…

gensim 实现 TF-IDF;textRank 关键词提取
目录
TF-IDF 提取关键词
介绍
代码
textRAnk 提取关键词 这里只写了两种简单的提取方法,不需要理解上下文,如果需要基于一些语义提取关键词用 LDA:TF-IDF,textRank,LSI_LDA 关键词提取-CSDN博客 TF-IDF 提取关键词…
NLP基础——TF-IDF
TF-IDF
TF-IDF全称为“Term Frequency-Inverse Document Frequency”,是一种用于信息检索与文本挖掘的常用加权技术。该方法用于评估一个词语(word)对于一个文件集(document)或一个语料库中的其中一份文件的重要程度。…

文本预处理:词袋模型(bag of words,BOW)、TF-IDF
文本预处理:词袋模型(bag of words,BOW)、TF-IDF这篇博客主要整理介绍文本预处理中的词袋模型(bag of words,BOW)和TF-IDF。
一、词袋模型(bag of words,BOW)…
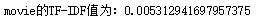
Python数据分析:文本分类
Python数据分析:文本分类
TF-IDF(词频-逆文档频率): TF,Term Frequency(词频),表示某个词在该文件中出现的次数 IDF,Inverse Document Frequency(逆文档频率…

【如何用大语言模型快速深度学习系列】从n-gram到TFIDF
感谢上一期能够进入csdn“每日推荐看”,那必然带着热情写下第二期《从n-gram到TFIDF》,这里引入一本《Speach and Language Processing》第三版翻译版本(语音与语言处理(SLP)),前半部分写的很好!里面连编辑…
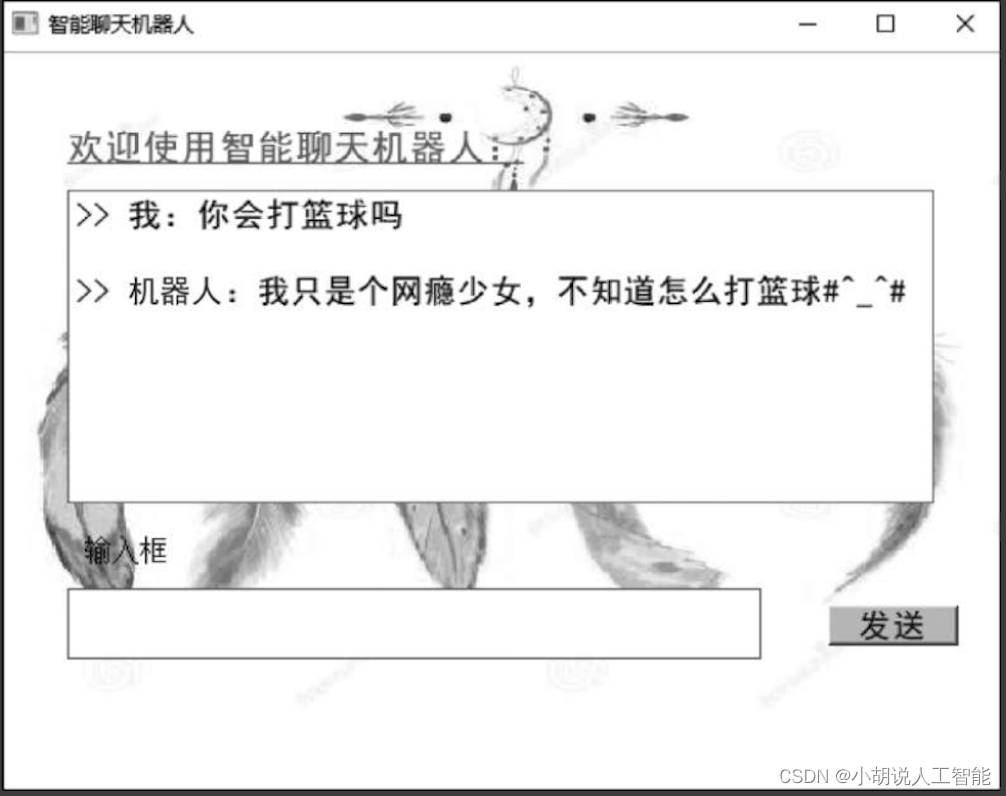
基于TF-IDF+Tensorflow+pyQT+孪生神经网络的智能聊天机器人(深度学习)含全部工程源码及模型+训练数据集
目录 前言总体设计系统整体结构图系统流程图孪生神经网络结构图 运行环境Python 环境TensorFlow 环境 模块实现1. 数据预处理2. 创建模型并编译3. 模型训练及保存4. 模型应用 系统测试1. 训练准确率2. 测试效果3. 模型应用 工程源代码下载其它资料下载 前言
本项目利用TF-IDF&…
使用sklearn生成TF-IDF词向量
写一个使用sklearn生成TF-IDF词向量的模板函数:
from sklearn import feature_extraction # 导入sklearn库, 以获取文本的tf-idf值
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerde…
基于TF-IDF+Tensorflow+PyQt+孪生神经网络的智能聊天机器人(深度学习)含全部Python工程源码及模型+训练数据集
目录 前言总体设计系统整体结构图系统流程图孪生神经网络结构图 运行环境Python 环境TensorFlow 环境 模块实现1. 数据预处理2. 创建模型并编译3. 模型训练及保存4. 模型应用 系统测试1. 训练准确率2. 测试效果3. 模型生成 工程源代码下载其它资料下载 前言
本项目利用TF-IDF&…
TF-IDF的信息论解释
在网页搜索系统中,搜索结果的排名取决于网页的质量和相关性。其中,网页质量的衡量通过Google公司发明的PageRank算法,而网页的相关性可以采用TF-IDF指标。下面首先介绍TF-IDF的由来,然后进一步阐述它的信息学原理。
TD-IDF 对于搜…
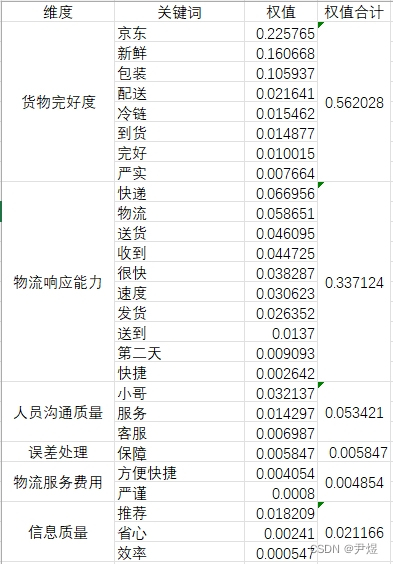
【NLP论文】02 TF-IDF 关键词权值计算
之前写了一篇关于关键词词库构建的文章,没想到反响还不错,最近有空把接下来的两篇补完,也继续使用物流关键词词库举例,本篇文章承接关键词词库构建并以其为基础,将计算各关键词的 TF-IDF 权值,TF-IDF 权值主…

NLP文本相似度(TF-IDF)
我们在比较事物时,往往会用到“不同”,“一样”,“相似”等词语,这些词语背后都涉及到一个动作——双方的比较。只有通过比较才能得出结论,究竟是相同还是不同。但是万物真的有这么极端的区分吗?在我看来不…

基于TF-IDF+TensorFlow+词云+LDA 新闻自动文摘推荐系统—深度学习算法应用(含ipynb源码)+训练数据集
目录 前言总体设计系统整体结构图系统流程图 运行环境Python 环境TensorFlow环境方法一方法二 模块实现1. 数据预处理1)导入数据2)数据清洗3)统计词频 2. 词云构建3. 关键词提取4. 语音播报5. LDA主题模型6. 模型构建 系统测试工程源代码下载…
【Python-Django】基于TF-IDF算法的医疗推荐系统复现过程
复现步骤 step1:
修改原templates路径,删除,将setting.py中的路径置空 step2:
注册app python manage.py startapp [app名称]
在app目录下创建static和templates目录 step3:
将项目中的资源文化进行拷贝
机器学习面试:tfidf的理解与应用
TFIDF的应用 分析某个元素在整体中的重要性,元素可以是类目,单词等 TFIDF的理解
给你一篇文章,该如何确定文章中哪些词是关键的呢?一个直接的想法是 对整篇文章进行分词,统计每个词出现的次数按照次数进行排序,出现次数越多的词重要性越高import jieba
from collections…

TF-IDF算法概述及模型构建
1.应用场景
我在构建搜索引擎的时候,需要构建一个排名算法。我最初版本的做法为,根据一篇文章中词汇出现的频率,对各个网页进行排序。这样会有一个很明显的缺点,当我们页面中出现很多**中止词(例如,the,1,…